Often you have pages, where dynamic and static parts mix. In our example, we're going to use a fictional movie theater's website. Here is the description of a few movies they are showing right now.The non-translateable parts are the title, the names of the actors and the name of the director.
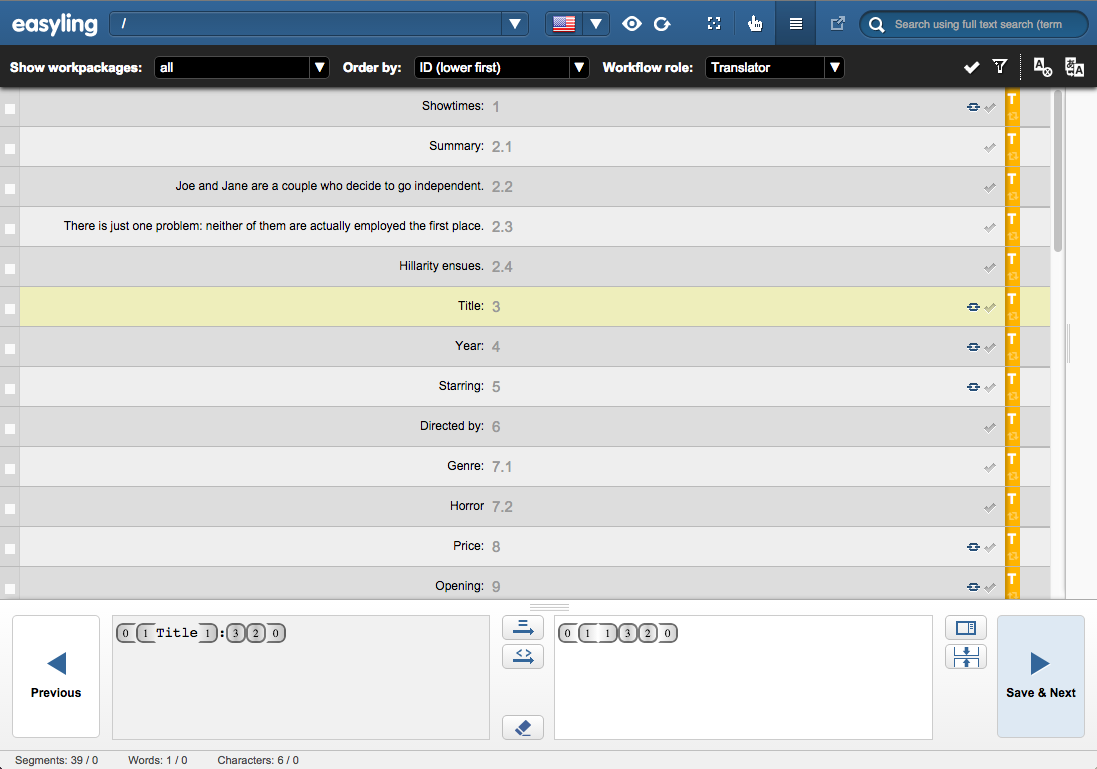
To demonstrate this in practice, let's translate this page in Easyling. Create a new project with this lesson's URL (lesson103.tutorial.easyling.com), and scan the page. If you open it for translation, you will see something like this:
To fix this, we're going to add a couple of rules at Dashboard - Advanced Settings - Pattern Matching. Here you can define the regular expressions for excluding certain things from the translation. For our particular case, this one will do:
(?:(?:Title|Starring|Directed by|Price|Opening|Showtimes|Year)\:)(.+)
Note that the tags within a given segment are ignore during matching (i.e. the <b> tags used for formatting), but they are not stripped and present in translation, as you can see it on the screenshot above.
Whitespace, however, is a different matter: whitespace is preserved, so you have to make sure your regexes cover that. To further complicate things, multiple whitespace characters are rendered as one by default in HTML (i.e. three spaces · · · will appear as a single one · ). Hence it is a good practice, to use the regular expression \s+ wherever whitespace is expected, as .+ or .* will not always catch them.
You can find an explanation for this particular regex here, which is the External pattern tester we link to on the page (see below).

The next step is to clean out the existing translations. Updating our regular expression will not affect our existing segments; however, after deleting them, re-scanning the page will hide the segments we do not want to translate and it will not be counted in the statistics.
Open the page for translation again, and click the search bar on the top. Search for the pattern /.+/, which will select all the source segments. Click the hourglass icon on the left, which will give you a warning:

After deleting the segments, scan the page again. Based on our regular expression above, certain segments will be hidden and will not show up on the workbench, nor in the statistics:
